A mapchan file configures the mapping of information
between the character sets used by devices and the internal
character set used by the system.
Each unique channel
map requires a multiple of 1024 bytes (a 1KB buffer)
for mapping the input and output of characters.
No buffers are required if no channels are mapped.
If control sequences are specified, an additional 1KB
buffer is required.
A method of sharing maps is implemented for channels that have
the same map in place.
Each additional, unique map allocates an additional buffer.
The maximum number of map buffers available on a system is configured
in the kernel, and is adjustable via the NEMAP
kernel parameter (see
``Hardware and device driver parameters'' in the Performance Guide).
Buffers of maps no longer in use are returned for use by other maps.
Example of a mapchan file
The internal character set is defined by the right column of the input map,
and the first column of the output map in place on that line.
The default internal character set is the 8-bit ISO 8859-1
character set, which is also known as dpANS X3.4.2 and
ISO/TC97/SC2.
It supports the Latin alphabet and can represent most European languages.
Any character value not given is assumed to be a straight mapping:
only the differences are shown in the mapchan file.
The left-hand columns must be unique.
More than one occurrence of any entry is an error.
Right-hand column characters can
appear more than once. This is ``many to one'' mapping.
Nulls can be produced with compose sequences or as part of an output string.
It is recommended that no mapping be enabled on the channel
used to create or modify the mapping files.
This prevents any confusion of the actual values being entered
due to mapping. It is also recommended that numeric
rather than character representations be used in most cases,
as these are not likely to be subject to mapping. Use comments
to identify the characters represented. Refer to the
ascii(M)
manual page and the hardware reference manual for the device being
mapped for the values to assign.
#
# sharp/pound/cross-hatch is the comment character
# however, a quoted # ('#') is 0x23, not a comment
#
# beep, input, output, dead, compose and
# control are special keywords and should appear as shown.
#
beep # sound the bell when errors occur
input
'a' 'b'
'c' 'd'
dead 'p'
'q' 'r' # p followed by q yields r
's' 't' # p followed by s yields t
dead 'u'
'v' 'w' # u followed by v yields w
compose 'x' # x is the compose key (only one allowed)
'y' 'z' 'A' # x followed by y and z yields A
'B' 'C' 'D' # x followed by B and C yields D
output
'e' 'f' # e is mapped to f
'g' 'h' 'i' 106 # g is mapped to h i j - one to many
'k' 0x6c 0155 'n' # k is mapped to l m n
control # the control sections must be last
input
E 1 # the character E is followed by
# 1 more unmapped character
output
FG 2 # the characters F G are followed by
# 2 more unmapped characters
All of the single letters above
preceding the ``control'' section must be in one of these formats:
'j' # quoted character
106 # decimal value
0x6a # hexadecimal value
0152 # octal value
All of the above formats are translated to single byte values.
The control sections (which must be the last in the file)
contain specifications of character sequences which should be passed
through to or from the terminal device without going through the normal
mapchan processing.
These specifications consist of two parts:
a fixed sequence of one or more defined characters indicating
the start of a no-map sequence,
followed by a number of characters of which the actual values
are unspecified.
To illustrate this, consider a cursor-control sequence which should be
passed directly to the terminal without being mapped.
Such a sequence would typically begin with a fixed escape sequence
instructing the terminal to interpret the following two characters
as a cursor position;
the values of the following two characters are variable, and depend
on the cursor position requested.
Such a control sequence would be specified as:
\E= 2 # Cursor control: escape = <x> <y>
There are two subsections under control:
the input section is used to filter data sent from the terminal
to UNIX, and the output section is used to filter data sent from
UNIX to the terminal.
The two fields in each control sequence are separated by white space,
that is the Space or Tab characters.
Also the number sign (#) introduces a comment,
causing the remainder of the line to be ignored.
Therefore, if any of these three characters are required in the specification
itself, they should be entered using one of alternative means of entering
characters, as follows:
^x
The character produced by the terminal on pressing the
<Ctrl> and x keys together.
\E or \e
The <Esc> character, octal 033.
\c
Where c is one of b, f, l, n, r or t,
produces Backspace, Formfeed, Linefeed, Newline, Carriage Return,
or Tab characters respectively.
\0
Since the NULL character can not be represented,
this sequence is stored as the character with octal value 0200,
which behaves as a NULL on most terminals.
\nn or \nnn
Specifies the octal value of the character directly.
\
followed by any other character is interpreted as that character.
This can be used to enter Space, Tab, or Hash characters.
Using character mapping
Certain characters in the ISO 8859-1 character set
are not assigned to specific keys since most terminals do not
have enough keys to assign one to each character.
Two methods of entering these characters are provided:
A dead key generates no output when pressed, but displays a character
when a subsequent key is pressed. Such a key can give you an
accented character which is not present on the keyboard as a specific key.
The character is a combination of a dead key
(the accent character) and the following key.
For example, pressing the ``´'' dead key followed by an ``a''
displays the accented character á.
To display the dead key character, press it twice.
Six dead keys are supported by the supplied mapchan files.
See
``Supported dead keys''
for details.
The following tables show which characters can be produced using the
dead keys.
There are six tables, each corresponding to a dead key.
The
second key is the key to press after pressing the dead key; the
value is the hexadecimal value of the resulting character.
Characters available with the caret dead key (^)
Second key
Value
Resulting character
a
0xe2
â - a caret
A
0xc2
 - A caret
e
0xea
ê - e caret
E
0xca
Ê - E caret
i
0xee
î - i caret
I
0xce
Î - I caret
o
0xf4
ô - o caret
O
0xd4
Ô - O caret
u
0xfb
û - u caret
U
0xdb
Û - U caret
<Space>
0x5e
^ - caret
^
0x5e
^ - caret
Characters available with the umlaut dead key (¨)
Second key
Value
Resulting character
a
0xe4
ä - a umlaut
A
0xc4
Ä - A umlaut
e
0xeb
ë - e umlaut
E
0xcb
Ë - E umlaut
i
0xef
ï - i umlaut
I
0xcf
Ï - I umlaut
o
0xf6
ö - o umlaut
O
0xd6
Ö - O umlaut
u
0xfc
ü - u umlaut
U
0xdc
Ü - U umlaut
y
0xff
ÿ - ij ligature
<Space>
0xa8
¨ - umlaut
¨
0xa8
¨ - umlaut
NOTE:
Some keyboards have an umlaut key.
This is not the same as the double
quote character, which is often used
to represent an umlaut/dieresis.
Characters available with the acute dead key (´)
Second key
Value
Resulting character
a
0xe1
á - a acute
A
0xc1
Á - A acute
e
0xe9
é - e acute
E
0xc9
É - E acute
i
0xed
í - i acute
I
0xcd
Í - I acute
o
0xf3
ó - o acute
O
0xd3
Ó - O acute
u
0xfa
ú - u acute
U
0xda
Ú - U acute
y
Oxdd
y ´ - y acute
Y
0xdd
Y ´ - Y acute
<Space>
0xb4
´ - acute
´
0xb4
´ - acute
Characters available with the grave dead key (`)
Second key
Value
Resulting character
a
0xe0
à - a grave
A
0xc0
À - A grave
e
0xe8
è - e grave
E
0xc8
È - E grave
i
0xec
ì - i grave
I
0xcc
Ì - I grave
o
0xf2
ò - o grave
O
0xd2
Ò - O grave
u
0xf9
ù - u grave
U
0xd9
Ù - U grave
<Space>
0x60
` - grave
`
0x60
` - grave
Characters available with the tilde dead key (~)
Second key
Value
Resulting character
a
0xe3
ã - a tilde
A
0xc3
à - A tilde
o
0xf5
õ - o tilde
O
0xd5
Õ - O tilde
n
0xf1
ñ - n tilde
N
0xd1
Ñ - N tilde
<Space>
0x7e
~ - tilde
~
0x7e
~ - tilde
NOTE:
Not all mapchan files support the ñ and Ñ characters.
Characters available with the cedilla dead key (¸)
Second key
Value
Resulting character
c
0xe7
ç - c cedilla
C
0xc7
Ç - C cedilla
<Space>
0xb8
¸ - cedilla
¸
0xb8
¸ - cedilla
Supported dead keys
Six dead keys are supported by the mapchan files provided with the
SCO OpenServer system.
The mapchan files for the following terminals use the
specified dead keys.
The other mapchan files do not provide dead keys, but can be modified
to do so:
mapchan
caret
acute
grave
umlaut
tilde
cedilla
file
(^)
(´)
(`)
(¨)
(~)
(¸)
ascii.spa
X
X
X
X
cons.bra
X
X
X
X
X
cons.ibm
X
X
X
X
cons.nor
X
X
X
X
X
cons.por
X
X
X
X
X
cons.spa
X
X
X
cons.850
X
X
X
X
X
X
cons.grk
X
X
cons.iso
X
X
X
X
digi.abicomp
X
X
X
X
X
digi.brascii
X
X
X
X
X
gvt.fra
X
X
gvt.ger
X
X
tispc.abicomp
X
X
X
X
X
tvi.fra
X
wy60.ger
X
X
wy60.fra.asc
X
X
wy60.fra.ans
X
X
w60.ibmfra.ans
X
X
w60.ibmfra.asc
X
X
wy60.ibm.ger
X
X
wy60.lat.asc
X
X
wy60.spa
X
X
X
X
wy60.spa.asc
X
X
wy60.spa.sk
X
X
ibm.spa
X
X
See the
mapchan(M)
manual page for a table of mapchan files and keyboards.
Compose sequences
Compose sequences allow you to press a
number of keys to generate a particular character.
The sequence
starts with the compose key and is completed by two further keys,
which specify the character input.
For example, the registered trademark
symbol (®) can be generated by pressing the following:
<compose key> r o
Some keyboards have a compose key marked as such.
To use this compose key you should refer to the manual for the
terminal.
All supplied mapping files use <Ctrl>_
(control underscore) as the character to introduce a compose sequence.
The PC console keyboard maps also use the <SysReq> key
to introduce compose sequences; on keyboards with 12 function keys,
the alternate compose key is the ``'' on the number pad.
The supplied compose sequences have alternatives.
This is because some sequences are needed to cover the cases
where characters are not present on the keyboard and so cannot
be used as part of a compose key sequence.
The following characters have not been used as elements of the
minimal compose sequence, since they are not present on certain
keyboards:
# $ @ [ \ ] ^ ` { | } ~
The following table shows all the characters available with the
various compose sequences:
 '' on the number pad.
'' on the number pad.
 system.
The mapchan files for the following terminals use the
specified dead keys.
The other mapchan files do not provide dead keys, but can be modified
to do so:
system.
The mapchan files for the following terminals use the
specified dead keys.
The other mapchan files do not provide dead keys, but can be modified
to do so:
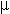 - micro sign
- micro sign